1. 용어 및 기능 정리
ㄱ. 범용 용어 정리
- Model : 어플리케이션이 무엇을 할지 정의하는 부분
- view : 사용자에게 시각적으로 보여지는 부분(UI)
- Controller : Model이 데이터를 어떻게 처리할지 알려주는 역할. 사용자에 의해 클라이언트가 보낸 데이터가 있으면 모델을 호출하기 전에 적절히 가공하고 모델 호출, 그다음 모델이 수행 완료하면 그 결과를 가지고 View에게 전달
- Controller : 중간 제어자로써 각 서비스와 연동되어 유지보수비용과 개발 비용을 대폭 줄여준다.
- Service : 요청한 정보를 가공하여 Controller에 넘긴다. 비즈니스로직을 수행한다.
- Repository : Entity에 의해 생성된 DB에 접근하는 메서드들을 사용하기 위한 인터페이스
- Entity : DB테이블에서 열은 Column이며 행은 엔티티 객체가 된다.
ㄴ. @어노테이션 정리
- @Entity : 이 클래스가 엔티티임을 알리고, JPA에서 정의된 필드들을 바탕으로 DB에 테이블을 만들어준다.
- @Builder : 해당 클래스에 해당하는 엔티티 객체를 만들 때 빌더 패턴을 이용해서 만들수 있게 해준다.
- @AllArgsConstructor : 선언된 모든 필드를 파라미터로 갖는 생성자를 자동으로 만들어 준다.
- @NoArgsConstructor : 파라미터가 아예 없는 기본생성자를 자동으로 만들어 준다.
- @Getter : 각 필드값을 조회할 수 있는 getter를 자동으로 생성
- @Setter : 각 필드값을 수정할 수 있는 setter를 자동 생성
- @ToString : 해당 클래스에 선언된 필드들을 모두 출력할 수 있는 toString메서드를 자동으로 생성해 준다.
- @ID : 해당 엔티티의 Primary Key가 될 값을 지정해 준다.
- @GeneratedValue : PK가 자동으로 1씩 증가하는 형태로 생설될지 등을 결정해준다.
- @ManyToOne,@OneToMany 등등 : 해당 엔티티와 다른 엔티티를 관계짓고 싶을 때 사용
- @Controller : Web MVC 코드에 사용된다. 해당 클래스가 Controller임을 명시, 주로 View 반환에 사용
- @Service : 비즈니스 로직이나 Repository layer 호출 하는 함수에 사용
- @Repository : 해당 클래스가 Repository임을 명시
- @RestController : 주로 Json/XML 형태로 객체 데이터를 반환
- @NoArgsConstructor : 파라미터가 없는 기본 생성자를 생성
- @AllArgsContstuctor : 모든 필드 값을 파라미터로 받는 생성자를 생성
- @RequiredArgsConstructor : final이나 @NonNull인 필드 값만 파라미터로 받는 생성자 생성
- @EqualsAndHashCode : 자바 빈을 만들 때 equals와 hashCode를 자주 오버라이딩 하는데 이걸 자동으로 해줌
- @ToString : toString() 메서드를 자동으로 실행 및 생성
- @PathVariable : URL의 마지막 변수를 처리해준다 ex)api/user/123
- @RequestQuery : 엔드포인트의 ? 뒤에 등장하며 변수를 담는다, key=value로 이루어져있고 &로 이어짐. ex)/api/member?days=3&unit=metric&time=10
- @RequestParam : 주소에 포함된 변수를 담는다 ex)/arp/member?id=2
- @GeneratedValue(stratege = generationType.???) : PK(primary key)값이 어떻게 들어갈 지 결정해준다.
- AUTO : DB방언 종류에 따라 자동으로 전략을 선택 (default)
- IDENTITY : 데이터베이스에 위임
- SEQUENCE : 들어오는 순서대로 생성
- @NotNull은 이름 드래도 Null만 허용하지 않음, null이 들어왔을 때 예상치 못한 오류나 문제가 생길 경우 사용
- @NotEmpty는 null과 ""둘다 허용하지 않게 한다. 하지만 " "은 허용이 된다.
- @NotBlank는 null ,"", " " 모두 허용하지 않는다.
ㄷ. ORM(Object Relation Mapping)
- 객체와 RDBMS의 데이터를 자동으로 매칭해 주는 것
- 객체 지향 프로그래밍은 클래스를 사용하고, RDBMS는 테이블을 사용
- 객체 모델과 관계 모델간의 불일치가 존재하지만 ORM을 통해 SQL을 자동으로 생성하여 문제 해결
- 장점
- 재사용 및 유지보수 편리성 증가
- DBMS에 대한 종속이 줄어든다
- 객체지향적인 코드로 더 직관적이고 비즈니스 로직에 더 집중 해줄 수 있다.
- 단점
- 완벽한 ORM으로만 서비스 구현이 어려움
- 프로시져(Procedure)가 많은 시스템에서 ORM의 객체 지향적인 장점 활용이 어려움
ㄹ. @Transactional : 범위 내 메서드가 트랙잭션이 되도록 보장
- 트랜잭션 : 데이터베이스의 상태를 변화시키기 위해서 수행하는 작업의 단위
- 4가지 특징
- 원자성(Atomicity) : 한 트랜잭션 내 실행한 작업들은 하나의 단위로 처리, 즉 모두 실패 또는 성공
- 일관성(Consistency) : 일관성있는 데이터베이스 상태를 유지한다.
- 격리성(Isolation) : 동시에 실행되는 트랜잭션들은 서로 영향을 미치지 않도록 해야한다.
- 영속성(Durability) : 트랜잭션을 성공적으로 마치면 결과가 항상 저장되어야 한다.
- 6가지 옵션
- isolation : 트랜잭션에서 일관성 없는 데이터 허용 수준을 설정
- propagation : 트랜잭션 동작 도중 다른 트랜잭션을 호출시 어떻게 할것인 지 설정
- noRollbackFor : 특정 예외 발생 시 rollback하지 않는다.
- RollbackFor : 특정 예외 발생 시 rollback한다.
- timeout : 지정시간 내 메소드를 수행하지 않으면 rollback(-1이면 timeout 미사용)
- readOnly : 트랜잭션을 읽기 전용으로 설정
ㅁ. 지네릭스
- 다양한 타입의 객체들을 다루는 메서드나 컬랙션 클래스에서 컴파일 시 타입을 체크해 주는 기능
- 즉, 실행하기전에 타입 일치를 확인하고 수정이 필요하다는 것을 알려준다.
- 타입의 안정성을 제공하고 코드가 간결해 지는데 도움을 준다.
ㅂ. enum(열거형)
- 여러 상수를 선언할 때 편리하게 사용하는 방법 중 하나 이다.
- 선언한 순서대로 0번부터 1, 2, 3... 으로 선정하여 코드가 간결해지고 많은 변수를 선언할 때 편리해진다.
2. 세션 정리
1)application.properties 대신 apllication.yml로 쓰기
- 세팅을 세부적으로 나누어 주고 들여쓰기를 사용하여 가독성을 높일 수 있다,
2)Repository
- repository 상속시 instends JpaRepository<메인클레스(ex.Memver), Pk타입(ex.Long)>과 같이 타입을 넣어준다
- findbyId 같은 건 JpaRepository가 상속되면서 자동으로 구현된다.
3. 영속성 컨텍스트
1)영속성 컨텍스트
- 엔티티를 영구 저장하는 환경
- 어플리케이션이 데이터베이스에서 꺼내온 데이터 객체를 보관하는 역할
- 엔티티 매니저를 통해 엔티티를 조회하거나 저장할 때 엔티티를 보관하고 관리 한다.
- JPA엔티티의 상태
- 비영속(New) : 영속성 컨택스트와 관계없는 새로운 상태, 실제 DB와 관련없고 Java객체인 상태
- 영속(Managed) : 엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리되고 있는 상태, 이와 같은 경우 데이터의 생성,변경등을 JPA가 추적하면서 필요하면 DB에 반영한다.
- 준영속(Detached) : 영속성 컨텍스트에서 관리되다가 분리된 상태
- 삭제(Removed) : 영속성 컨텍스트에서 삭제된 상태

2 )영속성 컨텍스트의 설계
ㄱ. 1차 캐시

- 서버가 떠있는 컴퓨터에 DB를 함께 두면 부하가 심하기에 따로 두어야 한다.
- 아플리케이션에서 데이터 조회가 아주 잦은데 그럴때마다 DB로 SQL쿼리 내는 일을 막아야한다
- 그래서 영속성 컨텍스트 내부에 1차 캐시를 둔다.
- find("memberB")와 같은 로직이 있을 때 먼저 1차 캐시를 조회
- 있으면 해당 데이터를 반환
- 없으면 그 때 실제 DB로 쿼리문을 보낸다.
- 그리고 반환하기 전에 1차 캐시에 저장하고 반환.
ㄴ. 쓰기 지연 SQL 저장소
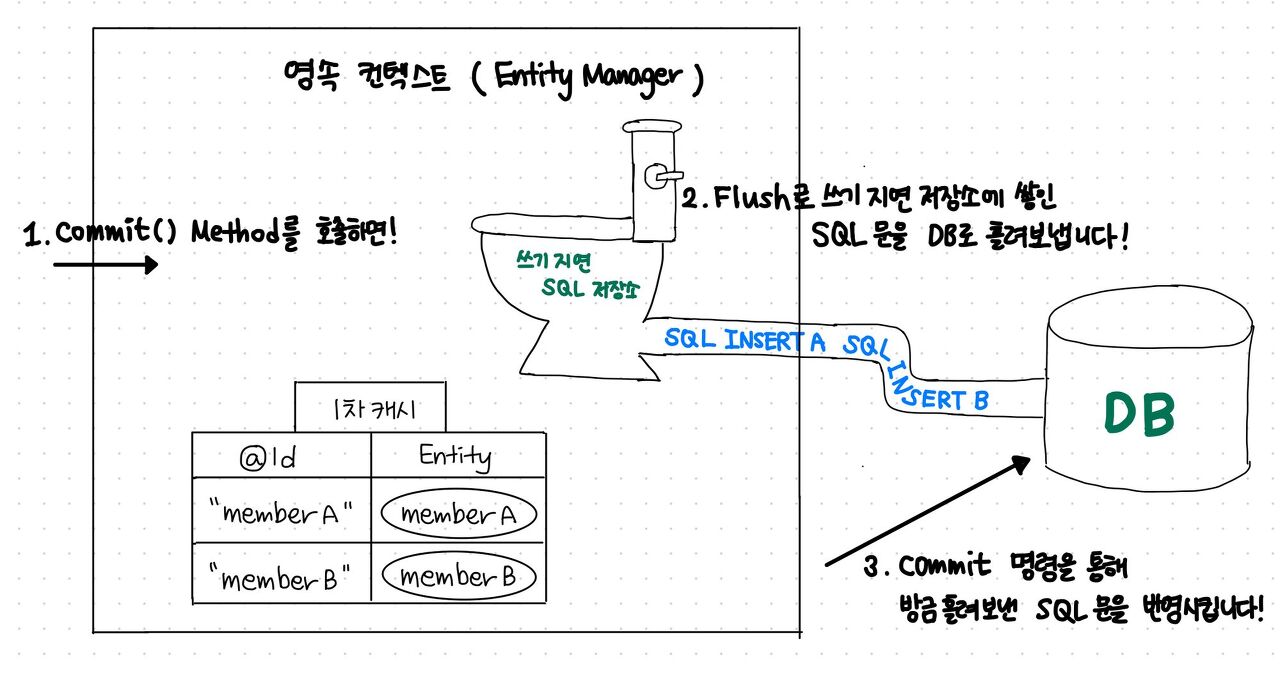
- 1차 캐시와 비슷한 맥락으로 MemberA, B를 생성할 때마다 DB를 다녀오는건 비효율적이기에 저장소를 두었다
- MemberA, MemberB를 영속화 하고
- entityManager.commit() 메서드를 호출하면
- 내부적으로 쓰기 지연 SQL 저장소에서 Flush가 일어나고
- "INSERT A", "INSERT B"와 같은 쓰지 전용 쿼리들이 DB로 흘러들어간다.
ㄷ. DirtyChecking을 통해 데이터의 변경을 감지해서 자동으로 수정

- 1차 캐시에는 DB의 엔티티 정보만 저장하는 것이 아니다
- 해당 엔티티를 조회한 시점의 데이터 정보를 같이 저장
- 그리고 엔티티객체와 조회 시점의 데이터가 다르다면 변경 발생을 인지 > 변경 부문을 UPDATE쿼리 작성
ㄹ. 데이터의 어플리케이션 단의 동일성을 보장
- java 컬렉션에서 값을 가져 올때 동일한 주소 값을 가져오듯이, 같은 reference를 불러오면 동일성을 보장해줍니다.
- 1차 캐시가 있기 때문에 가능
- 1차 캐시로 반복 가능한 읽기(REPATABLE READ) 등급의 트랜잭션 격리 수준을 DB가 아닌 어플리케이션 차원에서 제공 ( == 비교 시 true)
4. 연관관계
- 방향 : 단방향과 양방향 존재
- 다중성 :다대일,일대다,일대일,다대다 존재
- 연관관계의 주인 : 양방향일 때 연관 관계에서 관리 주체
1) 단방향과 양방향
- DB 테이블은 외래 키 하나로 양 쪽 테이블 조인 가능
- 두 객체 중 하나만 참조용 필드를 가지고 참조하면 단방향 관계, 두 객체 모두 면 양방향 관계
- 양방향 관계의 단점
- 객체 입장에서 양방향 매칭 시 복잡해 질 수 있다.
- 하나의 엔티티가 많은 엔티티와 관계를 맺을 때 복잡해 진다.
- 본적으로 단방향 매핑을 하고 나중에 역방향이 필요할 때만 추가하는 것이 좋다,
5. 프록시
1)프록시 개념
- JPA는 굳이 필요없는 DB 조회를 줄이면서 성능을 최적화한다고 말씀드렸죠? 이런 문제를 해결하려고 엔티티가 실제 사용될 때까지 데이터베이스 조회를 지연하는 방법을 제공하는데 이것을 지연 로딩이라 합니다. 그런데 지연 로딩 기능을 사용하려면 실제 엔티티 객체 대상에 데이터베이스 조회를 지연할 수 있는 가짜 객체가 필요한데 이것을 프록시 객체라고 합니다.
ㄱ.즉시 로딩과 지연 로등
- 즉시 로딩 : 엔티티를 조회할 때 연관된 엔티티도 함께 조회 @ManyToOne(fetch = FetchType.EAGER)
- 지연 로딩 : 연관된 엔티티를 실제 사용할 때 조회 @ManyToOne(fetch = FetchType.LAZY)
- 그래서 두 객체 중 하나만 참조용 필드를 가지고 참조하면 단방향 관계, 두 객체 모두 면 양방향 관계
- 엄밀히 말하면 양방향 관계라기 보다는 두 객체가 단방향 참조를 각각 가져서 양방향 관계처럼 사용하는 것
ㄴ. 영속성 전이
- 특정 엔티티를 영속성 상태로 만들어 연관되어진 엔티티도 함께 영속성 상태로 변경하는 것
- Cascade 라는 옵션을 통해 사용하며 수행.
- 옵션과 정보
6. AllInOneCode, DI
1)AllInOneController 코드의 한계점
- 한개의 클래스에 너무 많은 양의 코드 존재 : 코드 이해가 어려움
- 현업에서는 코드 추가 혹은 변경 요청이 계속 생김
2)DI(Dependency Injection) 의존성 주입
- A가 B에 의존한다는 것은 B가 변하면 그것이 A에 영향을 미친다고 할 수 있다.
- 의존관계를 인터페이스로 추상화하면, 더 다양한 의존관계를 맺을 수 있고, 실제 구현 클래스와 관계가 느슨해지고 결합도가 낮아진다.
- 즉 DI는 의존관계를 외부에서 결정하고 주입하여 주는 것이다.
ㄱ. 강한 결합과 약한 결합
public class Person {
private Chicken chicken;
public Person() {
this.chicken = new Chicken();
}
public void startEat() {
chicken.eat();
}
}
public class Chicken {
public void eat() {
System.out.println("치킨을 먹습니다.");
}
}- 위 코드에서 문제가 없어 보이지만 치명적인 단점이 있다.
- 1. Chicken 클래스가 없으면 Person 클래스를 정의 할 수 없다.
- 2 Chicken 클래스를 다른 종류의 음식으로 바꾸게 되면 Person 클래스의 코드 대부분이 변경된다.
- 즉 Person 클래스가 Chicken 클래스에 의존하고 있다는 것이다. => 강한 결합을 이루고 있다.
- 이러한 문제를 해결하기 위해 약한 결합을 이루게 하고 그 해결책으로 인터페이스가 있다.
- 인터페이스로 클래스를 나누어 준다면 하나가 변해도 다른 클래스의 내부적으로 코드 변경이 일어날 필요 없이, 생성자를 통해 객체를 받아 멤버변수에 대입하기만 하면 오브젝트를 변경 가능하게 해준다.
- 정리
- 객체 간 강한 결합을 이루게 되면 멤버 변수에 대한 오브젝트 변경시 코드의 변경이 많이 일어나 유지보수에 좋지 않다.
- 인터페이스를 통해 약한 결합을 이루게 하여 유지보수를 향상시킨다.
ㄴ. DI 구현
- DI는 의존관계를 외부에서 결정하는 것이기에, 클래스 변수를 결정하는 방법들이 곧 DI를 구현하는 방법이다.
- 런타임 시점의 의존관계를 외부에서 주입하여 DI구현이 완성된다.
- DI장점
- 의존성이 줄어든다
- 재사용성이 높은 코드가 된다
- 테스트하기 좋은 코드가 된다
- 가독성이 높아진다.
7. IOC와 Spring Framwork
1)IOC란?
- OC는 Inversion of Control의 약자로 말그대로 제어의 역전이다.
- 일반적으로는 아래와 같이 모든 작업을 사용자가 제어하는 구조이다.
- 객체 결정 및 생성 -> 의존성 객체 생성 -> 객체 내의 메소드 호출 하는 작업을 반복
- 하지만 IOC는 이 흐름을 바꾸어 제어의 흐름을 사용자가 컨트롤 하지 않고 위임한 특별한 객체에 모든 것을 맡기는 것
- 즉, IOC란 기존 사용자가 모든 작업을 제어하던 것을 특별한 객체에 모든 것을 위임하여 객체의 생성부터 생명주기 등 모든 객체에 대한 제어권이 넘어 간 것을 IOC, 제어의 역전
2)IOC기반인 스프링 프레임워크
- 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크로서 엔터프라이즈급 애플리케이션을 개발하기 위한 모든 기능을 종합적으로 제공하는 경량화된 솔루션
- Spirng Framework는 경량 컨테이너로 자바 객체를 담고 직접 관리합니다. 객체의 생성 및 소멸 그리고 라이프 사이클을관리하며 언제든 Spring 컨테이너로 부터 필요한 객체를 가져와 사용할 수 있습니다.
3)Spring Framwork의 특징 POJO, 평점한 자바 오브젝트
- POJO(Plain Old Java Object)는 이전 EJB(Enterpise JavaBeans)는 한가지 기능을 위해 불필요한 복잡한 로직이 과도하게 들어간 단점에 비해 getter/setter를 가진 단순 바자 오브젝트로 정의하고 있다.
- 따라서 의존성이 없고 추후 테스트 및 유지보수가 편리한 유연성의 장점을 가진다.
- 이로 인해 객체지향적인 다양한 설계와 구현이 가능해졌다.
7. Spring Bean
1)Spring Bean
- Spring IoC 컨테이너가 관리하는 자바 객체를 빈(Bean)이라고 한다.
- 즉 스프링에 의해서 관리당하는 자바 객체이다.
- @Component를 이용하여 Bean으로 등록하게 된다. 눈에 보이지 않더라도 사용하는 어노테이션의 소스를 확인해 본다면 @Component가 있는 것을 확인 할 수 있다.
- @Configuration과 @Bean을 이용해서 직접 Bean을 등록 할 수있다.
@Configuration
public class HelloConfiguration {
@Bean
public HelloController sampleController() {
return new SampleController;
}
}8. 인코딩과 디코딩
- 문자 코드를 기준으로 문자를 코드로 변환하는 것을 문자 인코딩(encoding)
- 코드를 문자로로 변환하는 것을 문자 인코딩(decoding)
1) Base64 이해와 Base62 비교
ㄱ. Base64
- 바이너리 데이터를 문자집합 각각 64개를 기준으로 변경하는 인코딩/디코딩 방식
- 대표적으로 이메일에 많이 사용하며, 인터넷 데이터 전송, 데이터 베이스 저장, 파일에 값 저장 등 사용
ㄴ. Base62
- 바이너리 데이터를 문자집합 각각 62개(정확히는 64개)를 기준으로 변경하는 인코딩/디코딩 방식
- Base64에서 0~63번째까지 중 62번째인 = 와 63번 째인 / 을 각각 -와 _ 로 바꾸어 준게 Base62이다.
- 이렇게 특수문자를 제거하였을 때 URL이나 파일명으로 사용할 수 있게 된다.
- 즉 Base64의 URL and Filename safe 버전이 되는 것이다.
1)Spring Bean
- Spring IoC 컨테이너가 관리하는 자바 객체를 빈(Bean)이라고 한다.
- 즉 스프링에 의해서 관리당하는 자바 객체이다.
- @Component를 이용하여 Bean으로 등록하게 된다. 눈에 보이지 않더라도 사용하는 어노테이션의 소스를 확인해 본다면 @Component가 있는 것을 확인 할 수 있다.
- @Configuration과 @Bean을 이용해서 직접 Bean을 등록 할 수있다
9. JWT(HS256과 RS256)
- JWT(JSON Web Token)는 base64 endoded string 3개가 점(.)으로 나누어진 토큰이다.
- 순서대로 header, payload, verify signatue이다.
- header에는 alg라는 key에 알고리즘 이름이 저장되어 JWT가 어떤 알고리즘으로 Hash되었는지 알수있다. JWT를 가진 서버와 클라이언트 모두 확인 가능하다.
- Verify signature에는 header와 데이터를 저장하는 payload를 "특정secret"으로 한 서명이 들어간다.
- secret을 가지고 있는 서버에서는 같은 방식으로 secret을 hash하여 header나 payload가 위변조 되지 않았는지 검증 할 수있다.
1) SHA-256 알고리즘
- 256비트로 구성되며 64자리 문자열을 반환한다.
- 이름에서 알 수 있듯 2^256만큼 경우의 수를 만들어 개인용 컴퓨터로 무차별 대입을 수행해 해시 충돌 사례를 찾으려고 할 때 많은 시간이 소요될 정도로 큰 숫자이므로 충돌로부터 비교적 안전하다고 평가받는다.
2) Hash 알고리즘
- 해쉬는 임의의 크기를 가진 데이터를 고정된 데이터 크기로 변화시키는 함수
- 해쉬 알고리즘을 유용하게 사용하기 위한 5가지 요구조건
- 단방향(One-way) : 해쉬 알고리즘은 복호화할 수 없다.
- 결정적(Deterministic) : 동일한 문서를 해쉬 알고리즘을 적용하면 똑같은 해쉬값을 얻어야 한다.
- 연산이 빨라야한다(Fast Computation) : 알고리즘을 잘 사용할 만큼 연산 속도가 빨라야 한다.
- 쇄도 효과(The Avalanche Effect) : 입력값에 아주 작은 변화에도 해쉬값이 완전히 달라지는 것을 의미
- 충돌 저항성(Must withstand collisions)
3) HS256(HMAC with SHA-256)
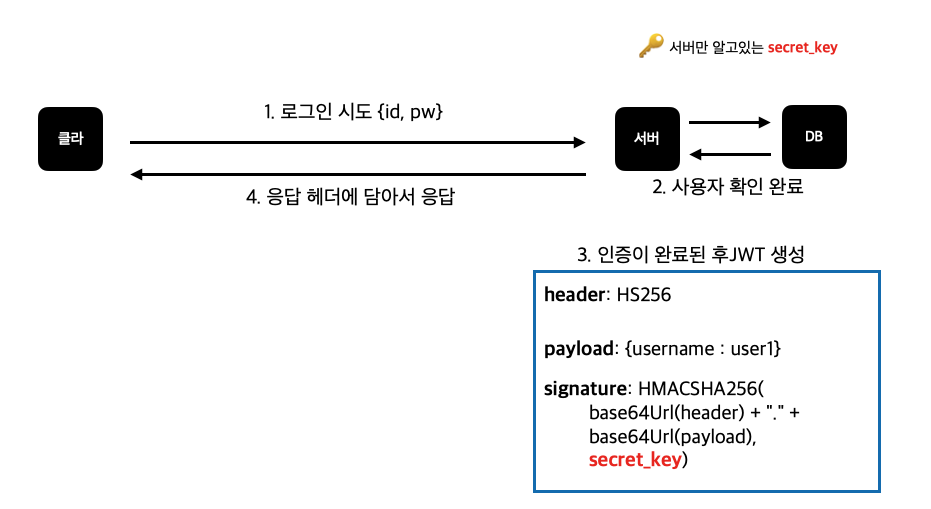
- 대칭 키를 사용하는 암호화 방식이다.
- Base64(Header) + Base64(Payload) + secret key 가 점(.)단위로 나누어 져있다.
- Signature는 "Header + Payload + secret 값" 을 HS256 알고리즘으로 암호화된다.
- 성된 Header, Payload, Signature 로 JWT 토큰을 만들어 클라이언트로 보내고, 클라이언트는 로컬 스토리지에 토큰을 저장합니다
- 클라이언트는 서버에 요청이 있을 경우, 토큰과 요청 내용을 같이 보냅니다.
- 서버에서는 Header 와 Payload 를 Base64 알고리즘으로 복호화한 뒤, 서버만 알고 있는 개인키를 가지고 다시 HS256 알고리즘을 이용해 암호화해보고, 클라이어트에서 보낸 토큰과 같은지 유효성 검증을 합니다.
4) RS256(RSA with SHA256)
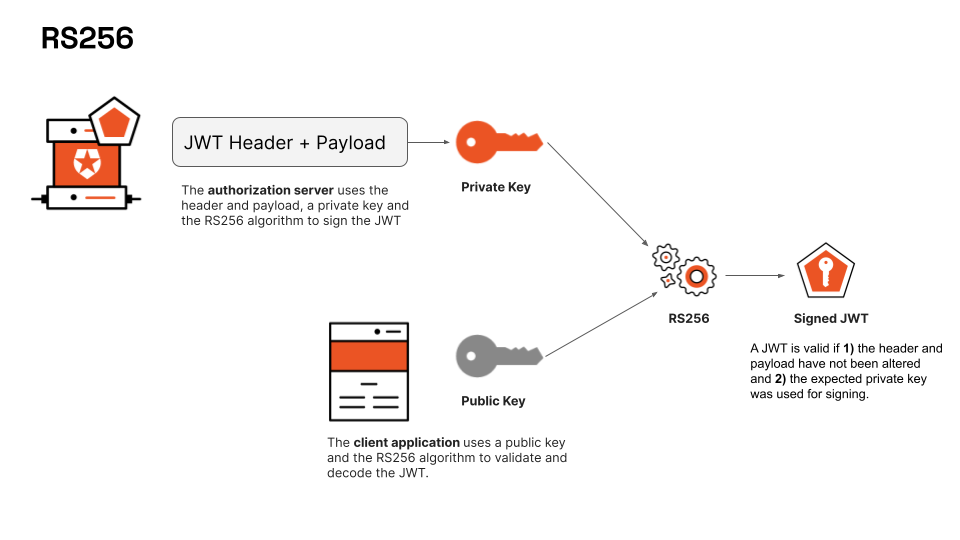
- 비 대칭 키를 사용하는 암호화 방식이다.
- 서버에서 Header, Payload 는 Base64로 인코딩된다.
- Header, Payload는 서버의 개인키로 암호화 Signature 를 만듭니다.
- 그리고 토큰을 만들어 클라이언트로 보낸다.
- 클라이언트는 서버에 요청을 보낼 때 토큰과 요청 내용을 같이 보낸다.
- 서버에서 토큰의 유효성을 검증하기 위해서, 공개키로 Signature를 복호화해본다.
- 비대칭키 암호화 알고리즘의 특징
- 공개키로 암호화한 것은 개인키로 복호화 가능(데이터 암호화 기능)
- 개인키로 암호화 한것은 공개키로 복호화 가능(전자서명 기능)